爬虫系列:穿越网页表单与登录窗口进行采集

上一期我们讲解了数据标准化相关内容,首先对单词出现的频率进行排序,之后对一些大小写进行转换,缩小 2-gram 序列的重复内容。
当我们真正迈出网络数据采集基础之门的时候,遇到的第一个问题可能是:“我怎么获取登录窗口背后的信息呢?”今天,网络正在朝着页面交互、社交媒体、用户产生内容的趋势不断地演进。表单和登录窗口是许多网站中不可或缺的组成部分。不过,这些内容还是比较容易处理的。
到目前为止,以前的示例当中网络爬虫和大多数网站的服务器经行数据交互时,都是用 HTTP 协议的 GET 方式去请求信息。在这一篇文章中我们重点介绍 POST 方法,即把信息推送给网络服务器进行存储和分析。
页面表单基本上可以看成是一种用户提交 POST 请求的方式,但这种请求方式是服务器能够理解和使用的。就像网站的 URL 连接何以帮助用户发送 GET 请求一样,HTML 表单可以帮助用户发出 POST 请求。当然我们也可以用一点儿点麻自己创建这些请求,然后通过网络爬虫把他们提交给服务器。
Python Requests 库
虽然用 Python 标准库也可以控制网页表单,但是有时用一点儿语法糖可以让生活更甜蜜。但你想做比 urllib 能够实现的基本 GET 请求更多事情时,可以看看 Python 标准库之外的第三方库。
Requests 库 就是这样一个擅长处理那些复杂的 HTTP 请求、cookie、header(响应头和请求头)等内容的 Python 第三方库。
下面是 Requests 的创建者 Kenneth Retiz 对 Python 标准库工具的评价:
Python 标准库 urllib2 为你提供了大多数 HTTP 功能,但是它的 API 非常差劲。这是因为它是经过许多年一步步建立起来的的——不同时期要面对的是不同的网络环境。于是为了完成最简单的任务,他需要耗费大量的工作(甚至要写整个方法)。
事情不应该这样复杂,更不应该发生在 Python 里。
和任何 Python 第三方库一样,Requests 库也可以用其他第三方 Python 库管理器来安装,比如 pip,或者直接下载 Requests 库源代码来安装。
提交一个基本表单
大多数网页表单都由一些 HTML 字段、一个提交按钮、一个在表单处理完成之后跳转的“执行结果”(表单 action 的值)页面构成。虽然这些 HTML 字段通常由文字内容构成,也可以实现文件上传或其他非文字内容。
因为大多数主流网站都会在它们的 robots.txt 文件里注明禁止爬虫接入登录表单,相关介绍可以参考这篇文章:爬虫系列:爬虫所带来的道德风险与法律责任。
比如下面是一个表单的源代码:
<form action="index.php?c=session&a=login" method=post name="form1">
<div class="input_title">用户名</div>
<div class="input_box" style="margin-bottom: 10px;">
<input id='username' name="username" />
</div>
<div class="input_title">密码</div>
<div class="input_box">
<input type="password" name="passwd" />
</div>
<div class="login_button">
<input type="submit" value="登 录" />
</div>
</form>
这里有几点需要注意一下:首先,两个输入字段的名称是 username 和 passwd ,这一点非常重要。字段的名称决定了表单被确认后要被传送到服务器上的变量名称。如果你想模拟表单提交数据的行为,你就需要保证你的变量名称与字段名称是一一对应的。
还需要表单的真实行为其实发生在 index.php?c=session&a=login。表单的任何 POST 请求其实都是发生在这个页面上,并非表单本身所在的页面。切记: HTML 表单的目的,只是帮助网站的访问者发送格式合理的请求,向服务器请求没有出现的页面。除非你要对请求的设计样式进行研究,否则就不要花太多时间在表单所在的页面上。
使用 Requests 库提交表单只需要简单的几行代码就可以实现,包括导入库文件和打印内容的语句:
import requests
params = {'username': 'admin', 'passwd': '5e_KR&pXJ9=J(c7d9P-twt9:'}
r = requests.post("http://www.test.com/admin/index.php?c=session&a=login", data=params)
print(r.text)
表单被提交之后,程序会返回执行页面的源代码,这些内容如下:
<frameset name="right" rows="64,9,*" cols="*" frameborder="no" border="0" framespacing="0">
<frame src="?c=index&a=top" name="top" noresize="noresize" scrolling="no">
<frame src="?c=index&a=controltop" name="controltop" noresize="noresize" scrolling="no">
<frameset cols="170,*" frameborder="no" border="0" framespacing="0" name="main1">
<frame src="?c=index&a=left" name="left" scrolling="auto" noresize>
<frame src="?c=index&a=main" name="main" scrolling="yes">
</frameset>
</frameset>
<noframes>
<body bgcolor='#FFFFFF' text='#000000'>
您的浏览器不支持框架!
</body>
</noframes>
由于我们通过的是 Requests 提交的内容,并没有在浏览器中进行提交所以才会出现上面的提示,但是我们已经登录成功了的。后面需要使用到浏览器采集内容的时候,我们再详述这部分内容。
这面那段代码可以处理很多简单的表单。下面是一个邮件订阅的表单代码,如下:
<form data-formid="4ea5f424-2d32-44c7-b603-887d06d6bde0" novalidate>
<input type="hidden" name="lifecyclestage" value="subscriber">
<input type="hidden" name="content_language" value="English">
<ul class="blog-subscribe-form__blog-list">
<li style="display: none;">
<input class="frequency" name="blog_default_blog_subscription" data-frequency="daily">
</li>
<li style="">
<input type="checkbox" id="hs-marketing-blog-sticky" name="marketing_blog_subscribe_check_box_via_comments" data-frequency="daily" data-frequency-field="blog_default_blog_subscription" data-subscription-type-id="98684">
<label for="hs-marketing-blog-sticky" class="blog-subscribe-form__checkbox">Marketing</label>
</li>
</ul>
<ul class="hs-error-msgs inputs-list" role="alert">
<li data-reactid=".hbspt-forms-0.1:$1.1:$email.3.$0">
<label class="validation blog-list-validation"></label>
</li>
</ul>
<div class="blog-subscribe-form__email-input-container">
<div class="blog-subscribe-form__email-input">
<label for="email-address">Email Address</label>
<input type="email" placeholder="" id="email-address" name="email" value="" required>
</div>
</div>
<ul class="hs-error-msgs inputs-list" role="alert">
<li data-reactid=".hbspt-forms-0.1:$1.1:$email.3.$0">
<label class="validation email-validation"></label>
</li>
</ul>
<input type="submit" value="Subscribe" class="blog-subscribe-form__button cta cta--primary-light cta--medium">
</form>
虽然第一次看到觉得有点恐怖,但是大多数情况下我们只需要关注两件事:
-
你想提交的数据字段名称,例如上面的
email -
表单的 action 属性,也就是表单提交后网站会显示的页面
单选按钮、复选按钮和其他输入
显然,并非所有的页面都只是一堆文本字段和一个提交按钮。 HTML 标准里面提供了大量可用的表单字段:单选按钮、复选按钮、下拉选项等。在 HTML5 里面,还有其他的控件,像滚动条(范围输入字段)、邮箱、日期等。自定义的 Javascript 字段可谓无所不能,可以实现取色器(colorpicker)、日历以及开发者能想到的任何功能。
无论表单的字段看起来多么复杂,仍然只有两件事需要关注:字段名称和值。字段名称可以查看源代码寻找 name 属性轻易获取。而字段值有的时候比较复杂,有可能是在表单提交之前通过 Javascript 生成的。取色器就是一个比较奇怪的表单字段,他可能会用 #f5c26b 这样的值。
如果你不确定一个输入字段值的数据格式,有一些工具可以追踪浏览器正在通过网站发出或接受的 GET 和 POST 请求的内容。之前提到过,追踪 GET 请求效果最好也是最直接的手段就是查看网站的 URL 链接,如果 URL 链接像这样:
https://pdf-lib.org/Home/SearchResult?Keyword=zabbix
那么请求的表单可能会是这样:
<form action="/Home/SearchResult" method="get">
<input type="text" value="" id="Keyword" name="Keyword">
<input type="submit" value="" id="Search">
</form>
下面是一个比较复杂的表单提交示例:
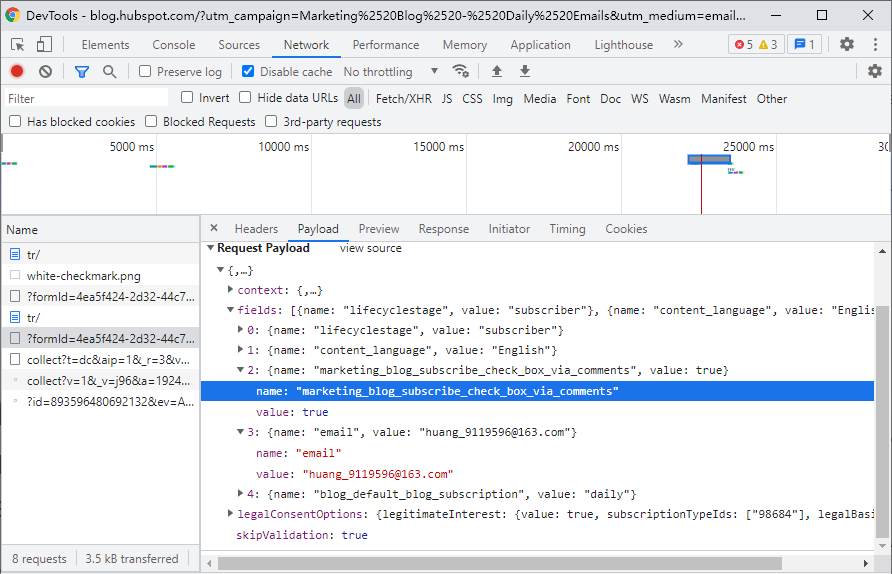
如果你遇到了一个看起来比较复杂的 POST 表单,并且像查看浏览器向服务器传送了那些参数,最简单的方法就是用 Chrome 浏览器的审查元素(inspector)或开发者工具查看。
总结
由于篇幅原因,今天只讲解了基本的表单、单选按钮、复选框和其他表单输入,以及如何通过 Requests 提交到服务器端。
在下一篇文章中我们将讲解提交文件、图像、处理登录、cookie、HTTP 基本接入认证和其他表单相关问题。
源代码已经托管于 Github,地址:https://github.com/sycct/Scrape_1_1.git
如果有任何问题,欢迎大家 issue。





