搜索引擎与爬虫
怎样查询恶意爬虫 IP

当今互联网爬虫种类繁多。为了绕过网站管理员的反爬虫策略,专业的爬虫往往会不断变换爬取手段。因此,依靠固定的规则来实现一劳永逸的完美防护是不太可能的。当恶意爬虫请求量达到一定程度后,往往造成服务器的 CPU 飙升,带来网站无法访问等业务中断问题。
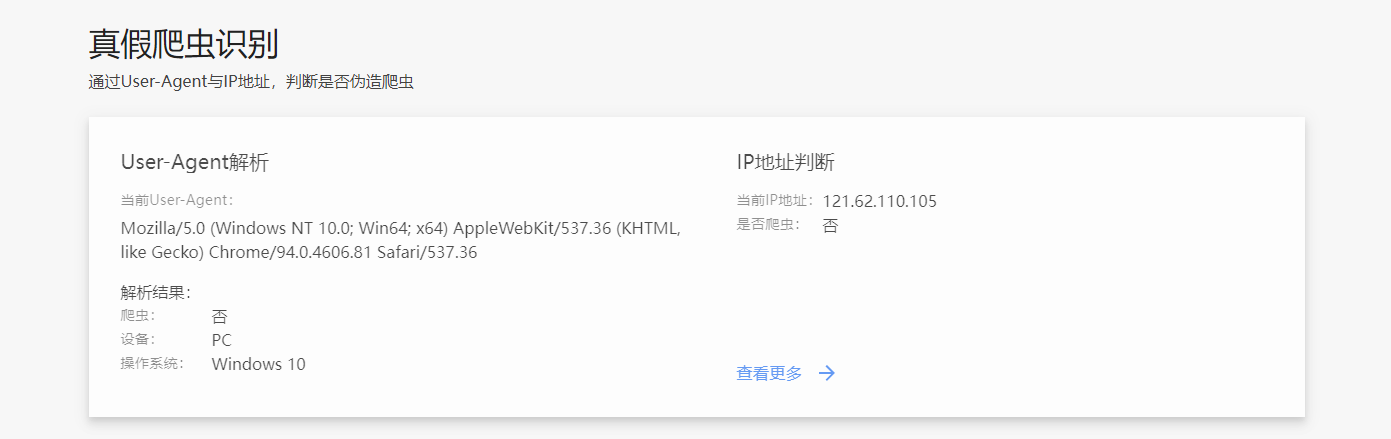
当我们无法确定某个 IP 是真正的爬虫还是伪造的恶意爬虫,我们可以在这个网站上确定爬虫是否伪造:爬虫识别,在爬虫识别这个网站资源的栏目里,有一个爬虫列表。
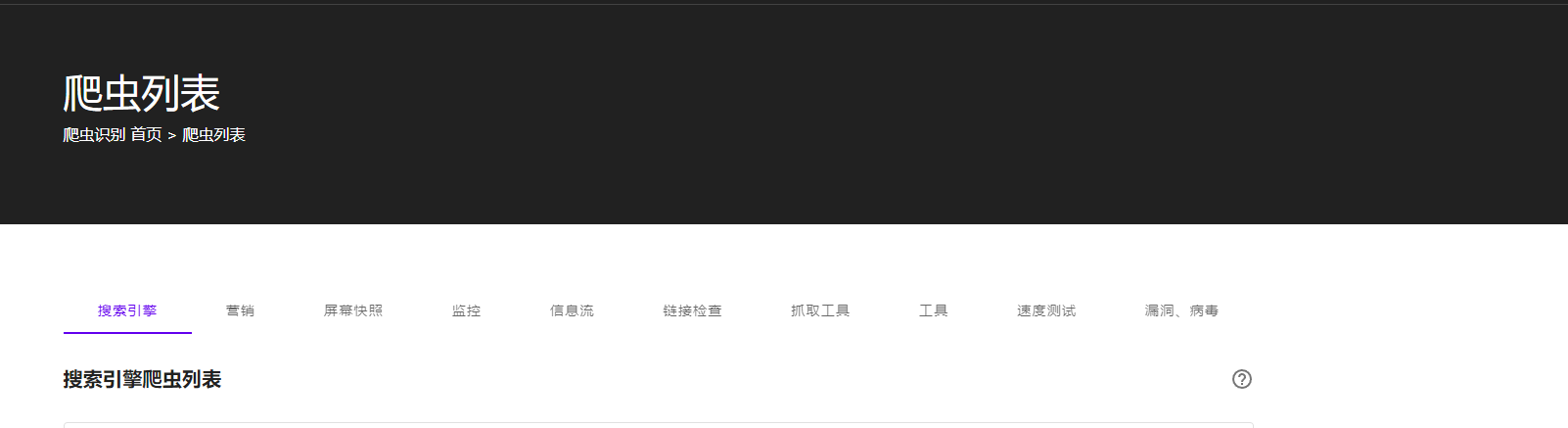
我们可以看到这个爬虫列表包含了:搜索引擎、营销、屏幕快照、监控、信息流、链接检查、抓取工具、工具、速度测试、漏洞病毒,这是我们常见的爬虫内容都可以在这里找到,我们现在要找的是恶意爬虫,所以我们找到抓取工具这一栏。
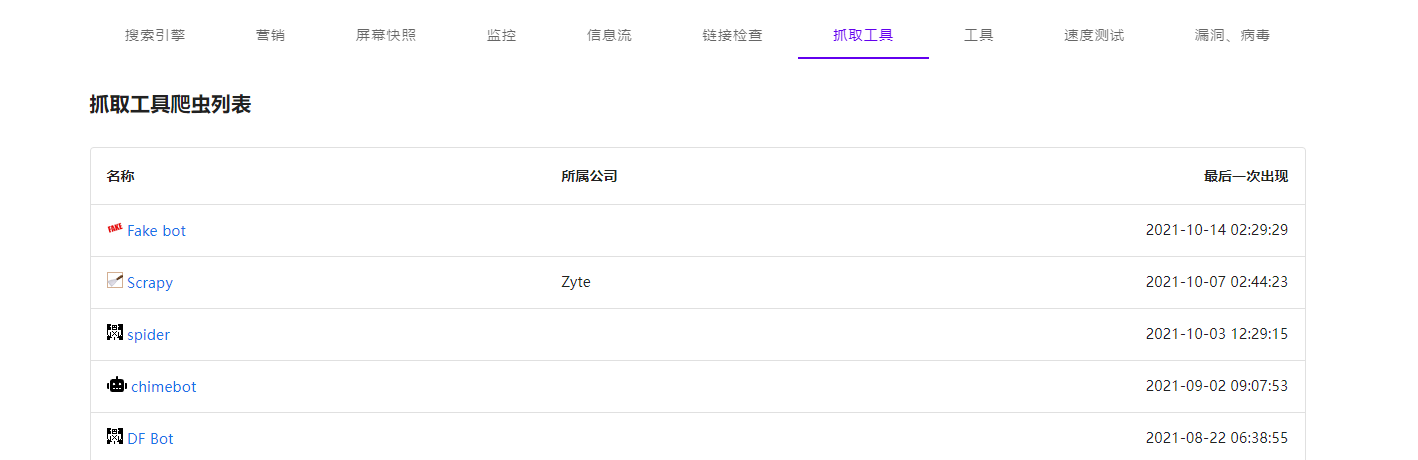
我们就可以看到里面有些伪造的爬虫,这里我们找到一个假冒百度的爬虫。
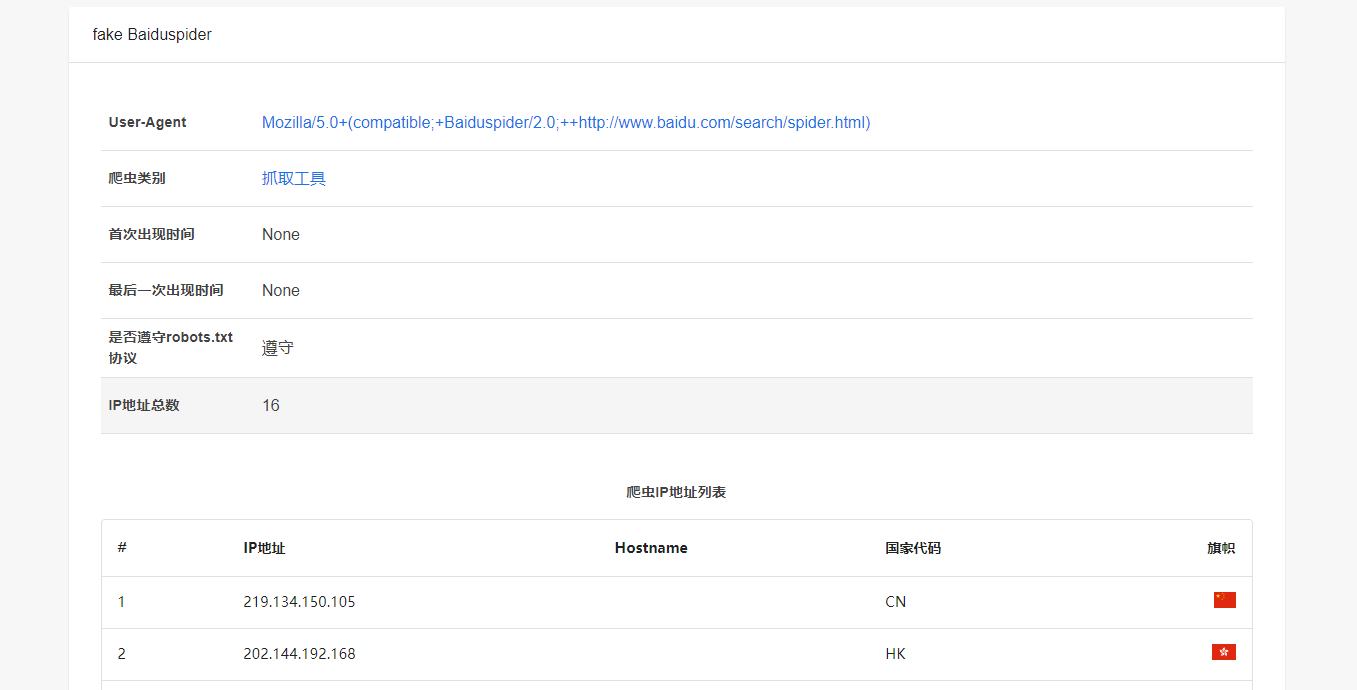
到这里还不是十分确定它的话,我们可以通过查询 IP 的方式找到这个爬虫是否是伪造的,回到网站首页,打开真假爬虫识别查询。
我们把刚才复制的 IP 输入红色框中。
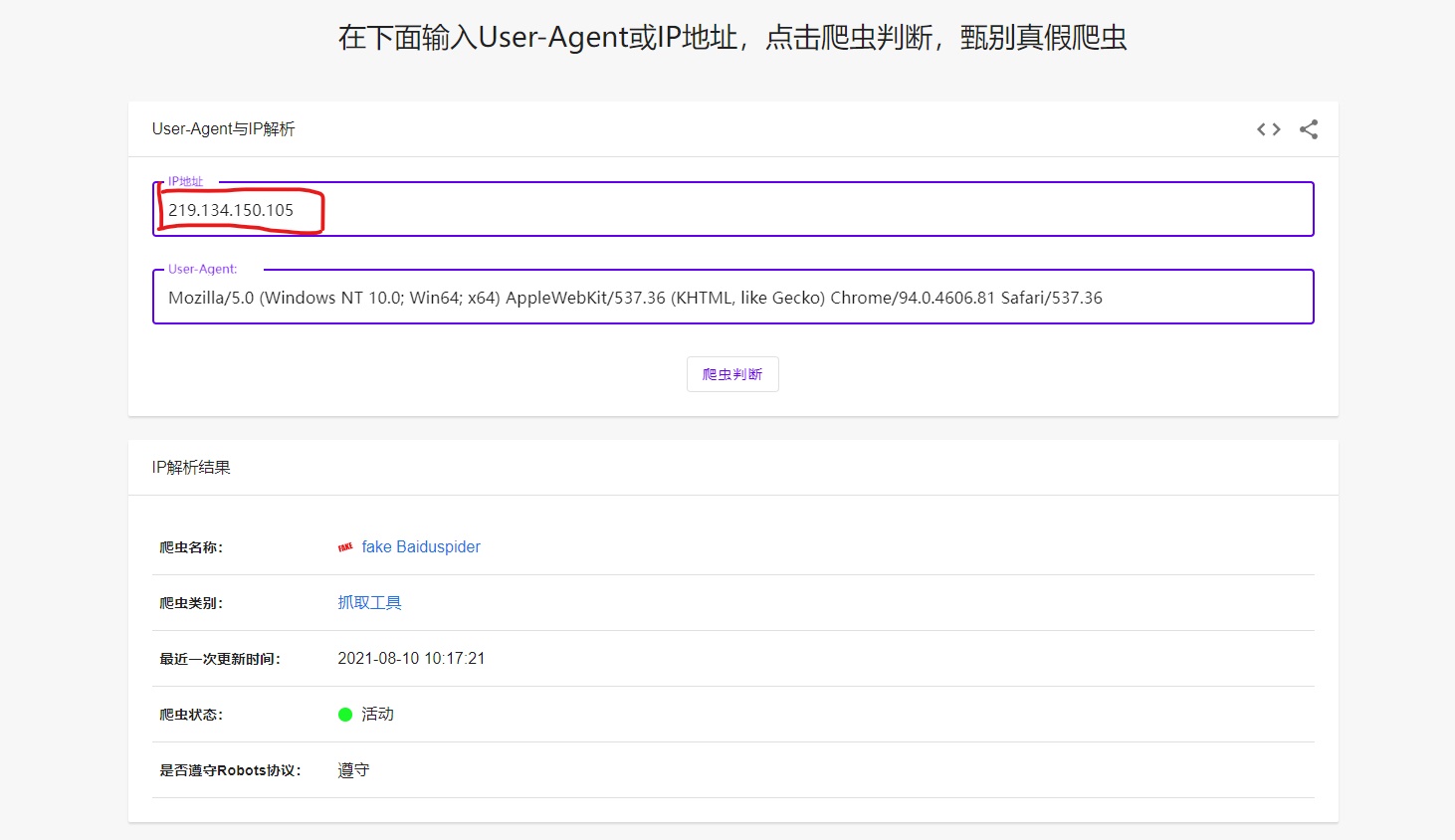
可以看到,这个 IP 是伪造百度蜘蛛的一个伪造爬虫。
这篇文章完整的介绍了如何通过爬虫识别这个网站,来查询恶意爬虫的 IP,希望对大家有帮助。